In today’s data-driven world, machine learning (ML) has become an integral part of many industries. From healthcare to finance and everything in between, ML models are being used to extract valuable insights and make data-informed decisions. However, developing and deploying ML models at scale can be a challenging task. This is where MLOps, a fusion of machine learning and operations, comes into play. In this article, we will explore the concept of MLOps and how to build an efficient MLOps pipeline.
Understanding MLOps
MLOps, short for Machine Learning Operations, is a set of practices and tools that streamline the development, deployment, and maintenance of ML models. It aims to bridge the gap between data science and IT operations, ensuring that ML models are not only accurate but also scalable, reliable, and maintainable.
The need for MLOps arises because traditional software development practices often fall short when applied to ML projects. ML models are different from conventional software; they are data-driven and require continuous monitoring and retraining to stay relevant. MLOps addresses these challenges by providing a framework for managing the entire ML lifecycle.
Building an MLOps Pipeline
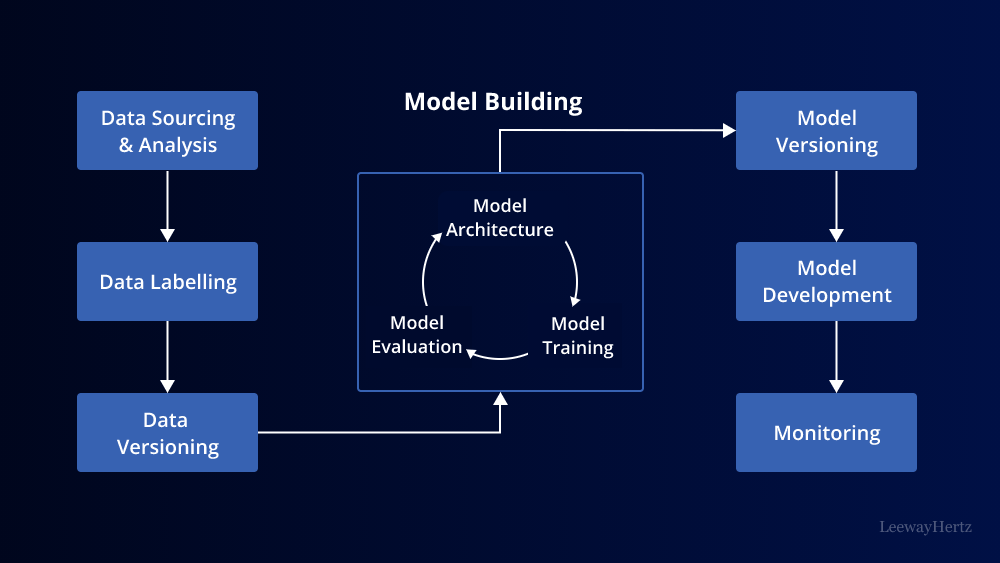
An MLOps pipeline is the core component of MLOps. It is a series of automated and interconnected steps that take an ML model from development to deployment and beyond. Building an efficient MLOps pipeline involves several key stages:
- Data Collection and Preprocessing: The first step in any ML project is gathering and cleaning data. An MLOps pipeline should automate data collection and preprocessing tasks to ensure data quality and consistency.
- Feature Engineering: Feature engineering is the process of selecting and transforming relevant features from the data. An automated pipeline can help data scientists experiment with various feature engineering techniques efficiently.
- Model Development: Data scientists and ML engineers work together to develop ML models using frameworks like TensorFlow or PyTorch. The pipeline should facilitate version control and collaboration, allowing teams to track changes and experiment with different algorithms.
- Model Training: Training ML models can be computationally intensive. An MLOps pipeline should leverage cloud resources and containerization to scale training processes as needed.
- Model Evaluation: Once trained, models need to be evaluated using metrics relevant to the problem domain. The pipeline should automate model evaluation and provide feedback to improve model performance.
- Model Deployment: Deploying ML models into production is a critical step. An efficient pipeline automates deployment to various environments, such as cloud, edge devices, or on-premises servers.
- Monitoring and Maintenance: ML models in production require continuous monitoring to detect drift and ensure they perform as expected. The pipeline should trigger alerts and initiate retraining when necessary.
- Scaling and Optimization: As user demand grows, the pipeline should be able to scale both infrastructure and models. Automated optimization techniques can help improve model efficiency.
- Documentation and Governance: Proper documentation and governance are essential for compliance and transparency. The pipeline should generate documentation automatically and enforce governance policies.
Key Benefits of an MLOps Pipeline
Building an efficient MLOps pipeline offers several advantages:
- Reduced Time to Market: Automation streamlines the ML development process, allowing organizations to deploy models faster and respond to changing market conditions.
- Improved Collaboration: MLOps pipelines facilitate collaboration between data scientists, ML engineers, and IT operations teams, ensuring that ML projects align with business goals.
- Scalability: Automated scaling of infrastructure and models enables organizations to handle increased workloads without manual intervention.
- Cost Efficiency: By optimizing resources and automating tasks, MLOps pipelines can reduce operational costs associated with ML projects.
- Reliability: Continuous monitoring and automated maintenance help ensure that ML models remain reliable and provide accurate results over time.
- Compliance and Governance: MLOps pipelines can enforce compliance and governance policies, ensuring that ML projects adhere to regulatory requirements.
Challenges in Implementing MLOps
While MLOps offers significant benefits, implementing it can be challenging. Some common challenges include:
- Cultural Shift: MLOps often requires a cultural shift within organizations, as it involves collaboration between traditionally siloed teams.
- Tooling and Infrastructure: Selecting the right tools and setting up the infrastructure can be complex, especially for organizations new to MLOps.
- Data Management: Data governance and data quality are crucial but can be difficult to manage effectively.
- Model Monitoring: Continuous monitoring of ML models requires the development of robust monitoring solutions.
- Skill Gap: Finding individuals with the necessary skills in both ML and operations can be challenging.
Conclusion
In an era where data-driven decision-making is paramount, MLOps is a critical discipline that empowers organizations to leverage the full potential of machine learning. Building an efficient MLOps pipeline is the key to successfully developing, deploying, and maintaining ML models at scale. While there are challenges in implementing MLOps, the benefits in terms of reduced time to market, improved collaboration, scalability, cost efficiency, reliability, and compliance make it a worthy investment for any organization looking to harness the power of machine learning.

Leave a comment