In the realm of artificial intelligence, one of the most captivating and rapidly evolving fields is generative AI. Among its numerous applications, image synthesis stands out as a transformative capability. Thanks to generative AI models, we have witnessed a remarkable leap in the creation of lifelike images, opening doors to countless possibilities in art, entertainment, design, and beyond.
The Rise of Generative AI
Generative AI models have come a long way since their inception. They have evolved from basic neural networks to more sophisticated architectures, enabling them to generate high-resolution images with astonishing realism. This evolution has been driven by advances in deep learning techniques and the availability of massive datasets for training.
The Pioneers: Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs)
Two foundational approaches have played a pivotal role in image synthesis: Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs).
VAEs are probabilistic models that aim to learn the underlying structure of data by mapping it into a lower-dimensional latent space. This enables them to generate new data points that share similarities with the training data. VAEs are known for their ability to produce diverse and expressive images while maintaining control over various aspects of the generated content.
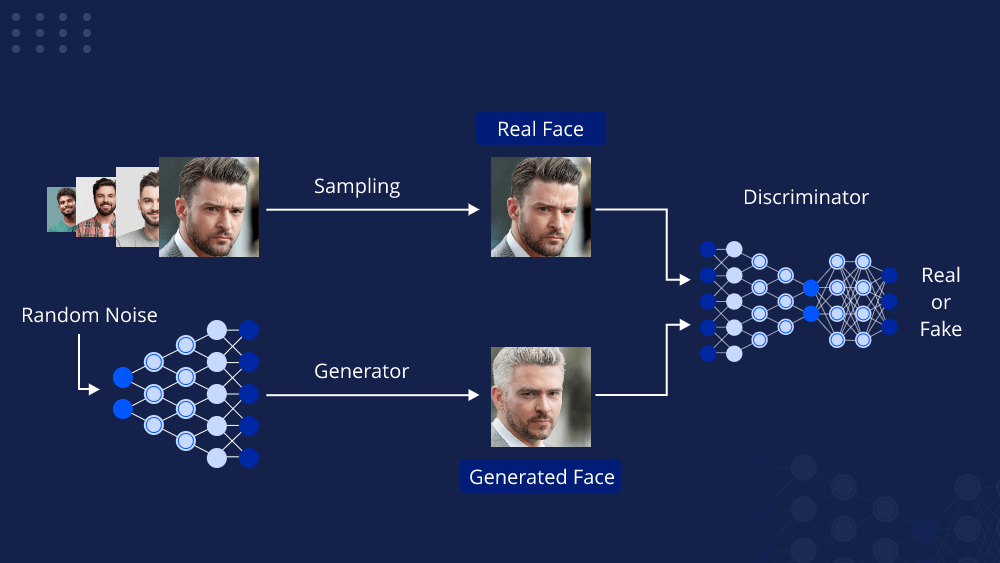
On the other hand, GANs take a different approach by employing a generative and a discriminative network in a competitive setup. The generative network tries to create realistic images to fool the discriminative network, which, in turn, becomes better at distinguishing real from fake. This adversarial training process results in images that often exhibit an uncanny level of realism.
Beyond Vanilla GANs: StyleGAN and BigGAN
The field of generative AI continued to advance rapidly, leading to the development of more specialized models. StyleGAN, for instance, introduced an innovative way to control the style and attributes of generated images. With StyleGAN, artists and designers can now tweak the appearance of generated content in real-time, making it a powerful tool for creative expression.
BigGAN, on the other hand, focuses on generating high-resolution images. It utilizes novel architectural techniques and large-scale training to produce stunningly detailed images, making it suitable for applications like super-resolution, content generation, and more.
Conditional Image Generation: cGANs and Pix2Pix
While traditional GANs generate images in an unsupervised manner, conditional GANs (cGANs) have been developed to allow for more control over the generated content. In a cGAN, the generator takes additional input, often in the form of class labels or reference images, to generate images that adhere to specific criteria. This has found applications in tasks like image-to-image translation, where models like Pix2Pix can transform images from one domain to another, such as turning sketches into photorealistic images.
The Ethical Implications
The capabilities of generative AI models for image synthesis are awe-inspiring, but they also raise significant ethical concerns. These models can generate highly convincing deepfake videos and images, potentially enabling malicious actors to create false narratives or spread misinformation. As a result, there is an urgent need for responsible AI development, robust detection methods, and ethical guidelines to mitigate these risks.
The Future of Generative AI in Image Synthesis
The journey of generative AI in image synthesis is far from over. Researchers are continuously pushing the boundaries of what is possible. Here are a few directions in which this field is heading:
- Few-shot learning: Developing models that require very little training data to generate high-quality images, making them more accessible and versatile.
- Interactive and controllable synthesis: Enhancing the user’s ability to manipulate and guide the image generation process, allowing for more precise and creative outputs.
- Multimodal generation: Expanding beyond images to generate complex multimodal content, such as images with associated text or audio.
- Real-time applications: Optimizing models for real-time image synthesis, opening up possibilities for live streaming, gaming, and interactive experiences.
Conclusion
Generative AI models for image synthesis have undergone a remarkable transformation, enabling us to create realistic and diverse images with unprecedented ease. From the early days of VAEs and GANs to the recent innovations in StyleGAN and BigGAN, the field continues to evolve. While we celebrate the creative and practical potential of these models, we must also address the ethical challenges they pose. As we look to the future, generative AI promises to revolutionize how we create and interact with visual content, reshaping industries and pushing the boundaries of human creativity.

Leave a comment