Transformers have revolutionized the field of natural language processing (NLP) and have become the go-to architecture for various tasks, including language translation, sentiment analysis, and text generation. One of the recent advancements in this area is the Decision Transformer, which builds upon the standard Transformer model to enhance its capabilities in handling decision-making tasks. In this article, we will explore what the Decision Transformer is and how to use it effectively within a Transformer architecture.
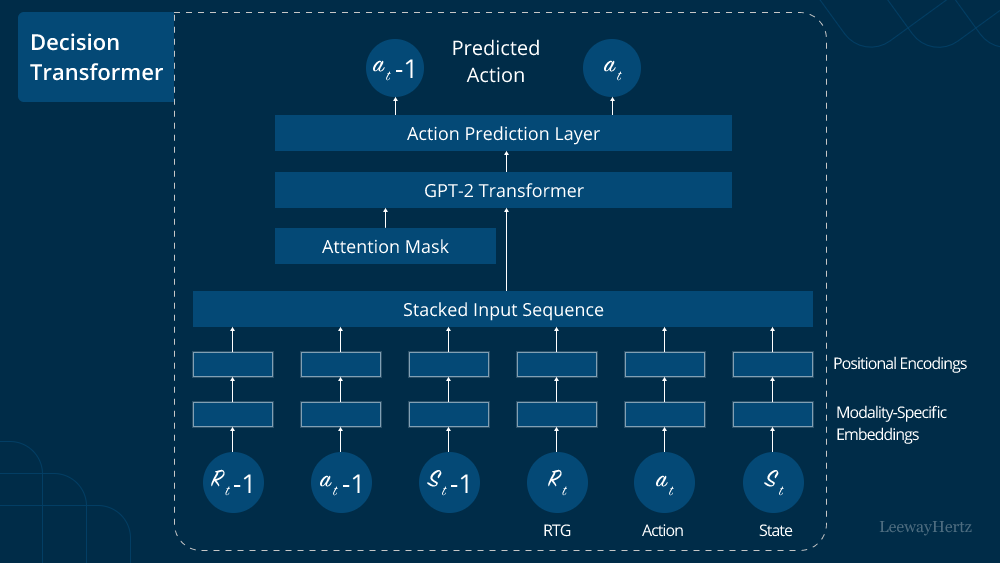
Understanding the Decision Transformer
The Decision Transformer is an extension of the classic Transformer model designed to address the challenges of decision-making problems. Traditional Transformers excel at sequence-to-sequence tasks, where the input and output are both sequences of tokens. However, decision-making tasks are different, as they require the model to make multiple sequential decisions based on incomplete information.
To enable the Transformer to make sequential decisions, the Decision Transformer introduces the concept of decision tokens. Decision tokens act as explicit signals to the model, instructing it to make a decision at specific points in the input sequence. These tokens carry decision labels, which guide the model’s decision-making process.
Incorporating Decision Tokens
To use the Decision Transformer in a Transformer architecture, you need to incorporate decision tokens into your input data. Suppose you have a decision-making task, such as an interactive story generation, where the model generates the next part of the story based on previous decisions. In that case, you need to format your input with decision tokens.
For instance, let’s consider a simple interactive story generation task where the model generates the story based on binary decisions at each step:
Input: [CLS] Once upon a time, there was a young knight on a quest. [SEP]
Decisions: [DEC] Go to the dark cave [SEP] [DEC] Follow the mysterious sound [SEP] [DEC] Rest under a tree [SEP]
The [CLS] token marks the beginning of the input, while [SEP] separates the context from the decisions. The [DEC] tokens indicate the points at which the model needs to make decisions, and the text following each [DEC] token provides the available choices.
Training the Decision Transformer
Once you have formatted your data with decision tokens, training the Decision Transformer follows a process similar to training a standard Transformer. However, there are some modifications to consider:
- Decision Loss Function: The training objective for the Decision Transformer involves both the sequence-to-sequence objective and the decision-making objective. To achieve this, you’ll need to design an appropriate loss function that considers the decision tokens’ accuracy along with the standard language modeling loss.
- Decision Token Position Embeddings: Since decision tokens are artificial tokens introduced into the sequence, they need their unique position embeddings. These embeddings should be incorporated into the model architecture to provide context-aware representations for decision-making.
- Model Evaluation: While evaluating the Decision Transformer, you need to focus not only on the quality of the generated text but also on the model’s ability to make accurate decisions based on the provided choices.
Benefits and Challenges of Decision Transformer
The Decision Transformer offers several advantages in tackling decision-making tasks:
- Interactivity: Decision tokens enable interactive communication with the model, allowing users to actively participate in the decision-making process.
- Flexibility: The model can handle varying numbers of decision points and choices, making it applicable to a wide range of decision-making scenarios.
- Robustness: Decision tokens explicitly instruct the model when to make decisions, reducing the chances of arbitrary or inconsistent choices.
However, there are also challenges to consider when using the Decision Transformer:
- Data Preparation: Formulating the input data with decision tokens can be complex, and collecting labeled data for decision-making tasks might be time-consuming and costly.
- Training Complexity: The additional decision-making objective adds complexity to the training process, potentially requiring more computational resources.
- Handling Long Sequences: Decision-making tasks with long sequences may lead to increased computational and memory requirements, affecting model performance.
Conclusion
The Decision Transformer is a powerful extension of the Transformer model, enabling it to handle decision-making tasks effectively. By incorporating decision tokens and designing appropriate loss functions, you can utilize the Decision Transformer to build interactive and robust systems for various decision-making applications. While it comes with some challenges, the potential benefits make it a compelling approach in the realm of NLP and AI.
To Learn More:- https://www.leewayhertz.com/decision-transformer/

Leave a comment